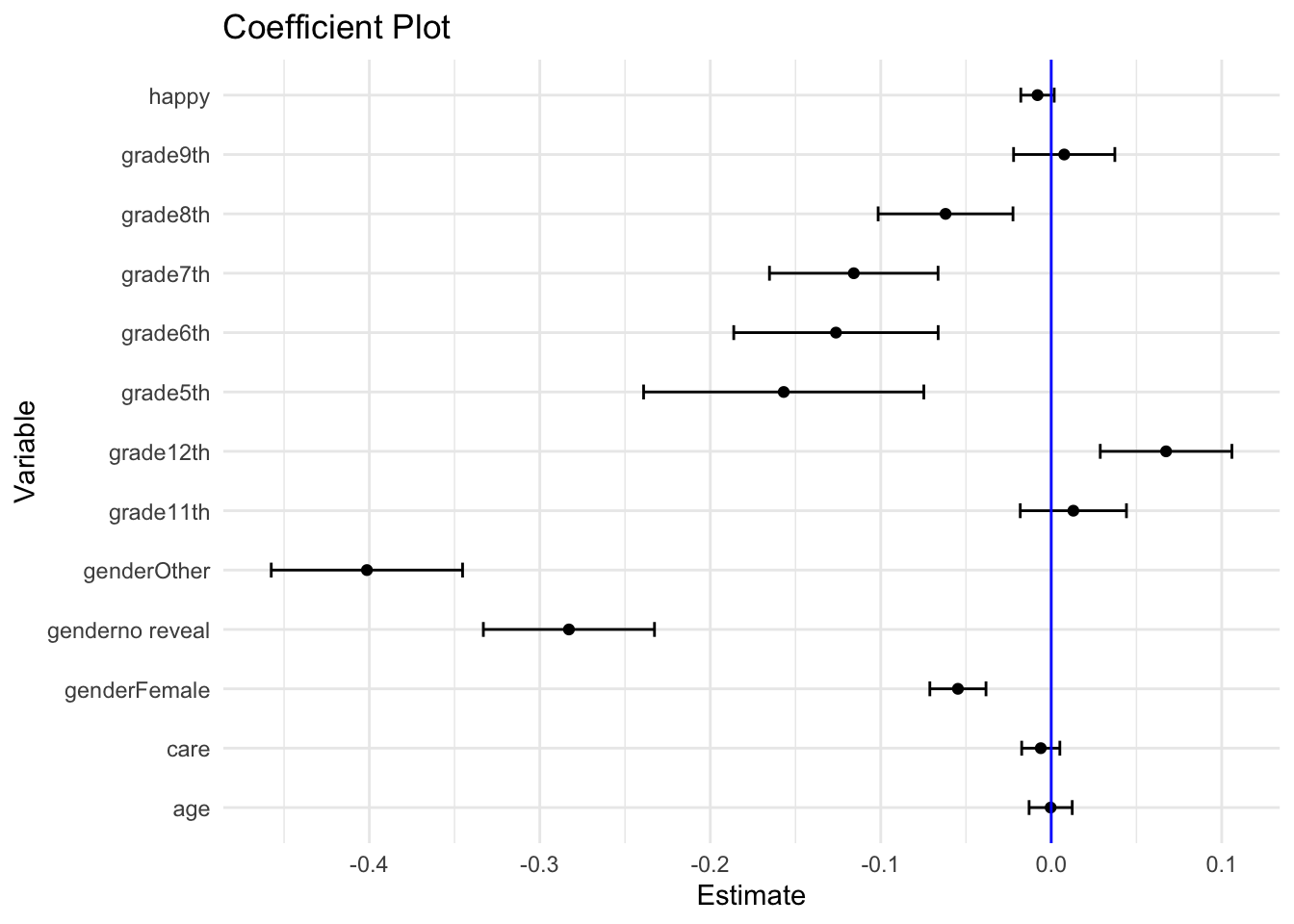
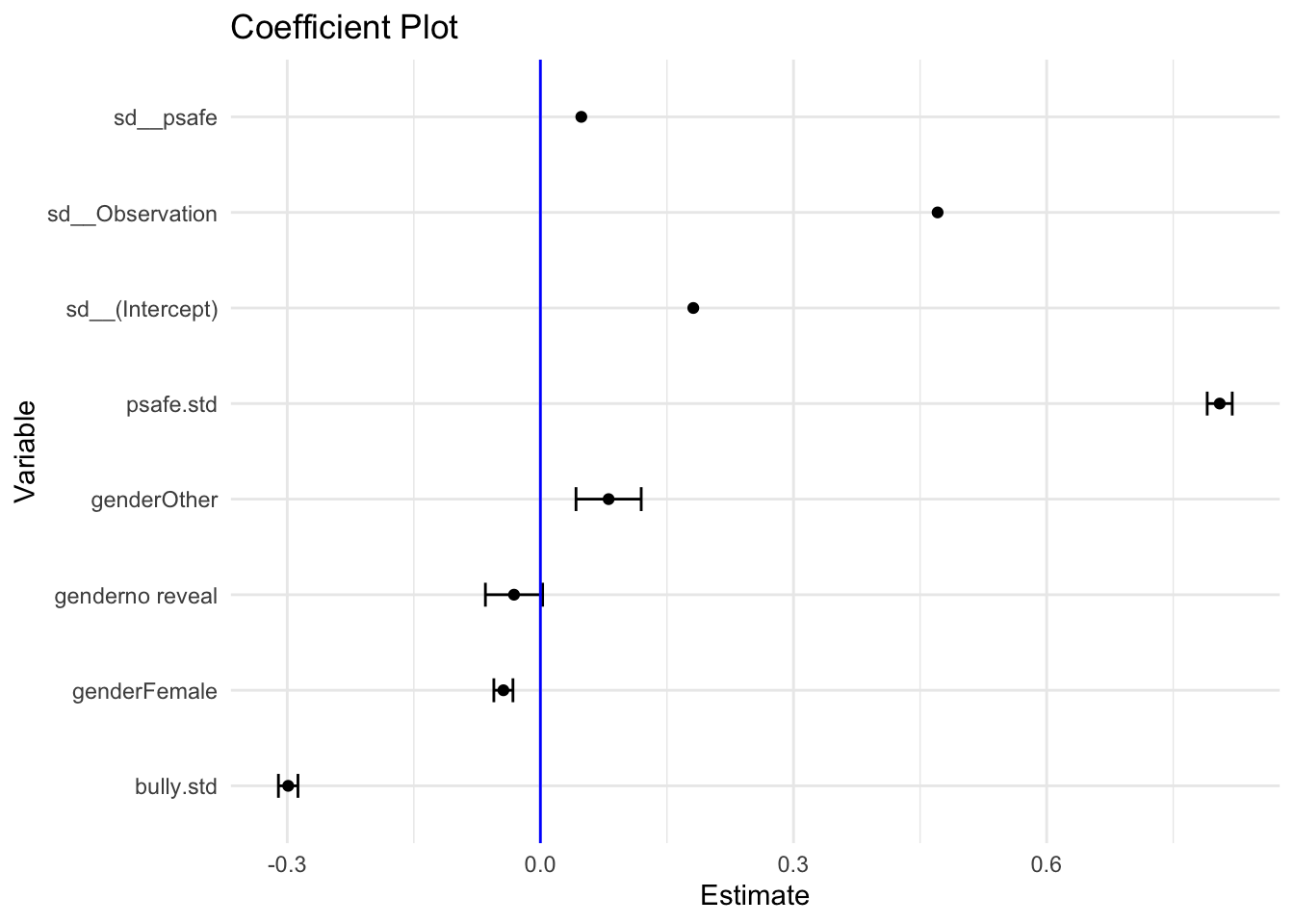
Coefficient plots provide a visually intuitive way to present the results of regression models. By displaying each coefficient along with its confidence interval, we can quickly discern the significance and magnitude of each coefficient.
As usual, we will turn to the tidyverse to make our plots. We will use the broom.mixed package to quickly get our coefficients, and then ggplot to make a nice plot of them. This is a great plot for a lot of final projects.
To illustrate, say we have a fit multilevel model such as this one on the Making Caring Common Data (the specific model here is not the best choice for doing actual research):
arm::display( fit )
lmer(formula = esafe ~ age + grade + gender + happy + care +
(1 | ID), data = dat)
coef.est coef.se
(Intercept) 3.50 0.20
age 0.00 0.01
grade11th 0.01 0.03
grade12th 0.07 0.04
grade5th -0.16 0.08
grade6th -0.13 0.06
grade7th -0.12 0.05
grade8th -0.06 0.04
grade9th 0.01 0.03
genderno reveal -0.28 0.05
genderOther -0.40 0.06
genderFemale -0.05 0.02
happy -0.01 0.01
care -0.01 0.01
Error terms:
Groups Name Std.Dev.
ID (Intercept) 0.25
Residual 0.65
---
number of obs: 7666, groups: ID, 39
AIC = 15291.2, DIC = 15103.4
deviance = 15181.3
In general you will want to make sure your plotted variables are on a similar scale, e.g., all categorical levels or, if continuous, standardized on some scale. Otherwise the points will be hard to compare to one another.
To do this we might standardsize continuous variables like so:
Here we left our residual variances on to get some scale. E.g., the schools vary more than the girl-boy gap (boys are our reference category). We can now say things like a one standard deviation increase in bullying corresponds to a -0.3 standard deviation change in emotional safety. Physical safety, not unsurprisingly, is heavily predictive of emotional safety.
The small group size of those who chose not reveal their gender makes the confidence interval wider than for the other coefficents. Overall, this large survey is giving us good precision.